

Kreditinstitute weltweit schreiten in der Digitalisierung mit Hilfe von Künstlicher Intelligenz voran. Dabei vernachlässigen sie jedoch den Großteil ihres wertvollen Datenschatzes: Unstrukturierte Daten. Dabei liegen gerade hier zahlreiche Chancen, dies es zu nutzen gilt.

Mithilfe von Künstlicher Intelligenz können Banken mehr aus ihren Daten herausholen.
Partner des Bank Blogs
Datengetriebe Prozesse werden von Finanzdienstleistern weltweit forciert, weil sie starke Geschäftsmodelle versprechen. So geben Banken aktuell laut einer Bloomber-Studie über 10 Prozent ihrer Einnahmen für die Entwicklung neuer Technologien aus. Doch trotzdem ist die KI-Strategie vieler Geldhäuser unbefriedigend. Der Grund: Es werden fast ausschließlich Daten verwendet, die für Maschinen aufbereitet und dadurch für sie einfach lesbar sind, sogenannte strukturierte Daten.
Ein noch nicht erschlossenes Potenzial liegt in Rohdaten wie Dokumenten, Präsentationsfolien, E-Mails oder Audiomitschnitten, sogenannten unstrukturierten Daten, welche im Rahmen von Big Data verfügbar gemacht wurden. Diese sind für Computer und intelligente Programme schwerer zu durchzusuchen und auszuwerten, weil sie nicht für einen bestimmten informatischen Kontext aufbereitet wurden. Unstrukturierte Daten stellen laut einer Studie von Fintech Futures ungefähr 80 Prozent der vorhandenen Datenmenge bei Finanzdienstleistern dar.
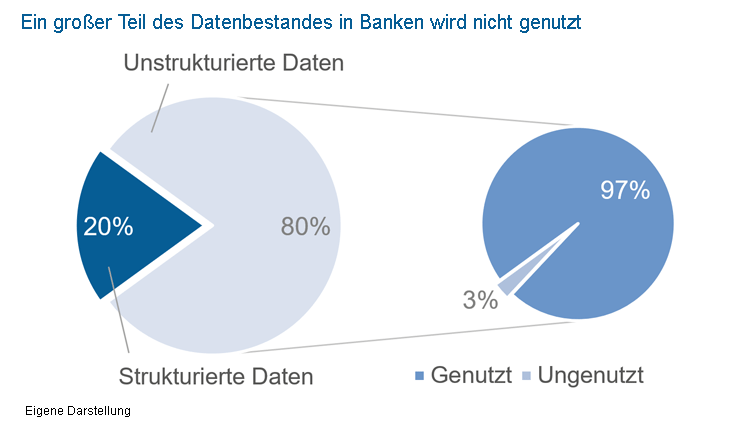
Der größte Anteil des Datenbestands von Finanzdienstleistern betrifft unstrukturierte Daten. Von diesen werden aber nur 3 Prozent genutzt.
Viele Geldhäuser berücksichtigen diesen Berg an Daten jedoch in ihren Prozessen noch nicht. Nur drei Prozent der vorhandenen unstrukturierten Daten werden bei Banken zum aktuellen Zeitpunkt analysiert. Dies liegt insbesondere darin begründet, dass viele Institute mit der Integration von grundlegenderen KI-Modellen vollständig ausgelastet sind. Trotzdem sollten Entscheider unstrukturierte Daten bereits jetzt zu einer zentralen strategischen Priorität machen.
Bereicherung vorhandener KI-Modelle durch unstrukturierte Daten
Die naheliegendste Strategie zur Nutzung unstrukturierter Daten liegt für Entscheider darin, bereits produktive KI-Modelle durch Erkenntnisse aus unstrukturierten Daten zu bereichern. Denn viele konventionelle Künstliche Intelligenzen können nur einen eingeschränkten Erkenntnisgewinn generieren, weil die zugrundeliegenden Daten homogenen Ursprungs sind. Die Verwendung differenzierterer Parameter wie beispielsweise des Bewegungsprofils oder von Vertragsdaten kann dabei helfen, auch Grenzfälle sicher abzudecken.
Ein konkreter Use Case hierfür ist die Anreicherung von intelligenten Algorithmen in der Betrugserkennung. In diesem Feld werden aktuell insbesondere Zahlungsverkehrsdateien und Informationen zu Konten von Sendern und Empfängern sowie Informationen zu aktuellen Betrugsmaschen verwendet. Durch die Verwendung unstrukturierter Daten im Trainingsprozess solcher Modelle können Erkenntnisgewinne aus der Meta-Ebene gewonnen werden. So kann beispielsweise die Nutzung von Standortdaten und gegebenenfalls sogar von ganzen Bewegungsprofilen betrügerische Transaktionen mit einer höheren Treffsicherheit bestimmen.
Trends durch vollumfängliches Monitoring erkennen
Ein besonderer Mehrwert wird dadurch erschlossen, dass unstrukturierte Daten auch übergreifend analysiert werden. Durch die Abdeckung unterschiedlichster Datentypen von Dokumenten bis hin zu Videos können somit auch Verbindungen zwischen unterschiedlichen Datenquellen hergestellt werden.
Konkrete Anwendung findet dies unter anderem in der Identifizierung von individuellen Kundenbedürfnissen. So können beispielsweise Kündigungen vorgebeugt, grundlegende Finanzierungspräferenzen erkannt und Finanzierungswünsche identifiziert werden, die sich durch die individuelle Lebenssituation des Kunden entwickelt haben. Grundlage dafür ist das Nutzen unterschiedlicher Daten-Quellen, welche differenziert über mehrere qualitative Ebenen den Kunden widerspiegeln. Beispielsweise durch die Auswertung seiner Banking-Gewohnheiten, Lebensphasenentwicklung und Kommunikation mit seinem Bankberater.
Durch die Nutzung von externen Daten, die über den einzelnen Kunden hinausgehen, können Finanzdienstleister außerdem weiterführende Trends erkennen. So hat beispielsweise die HSBC bereits 2020 einen KI-Fond entwickelt, welcher anhand der Auswertung von unstrukturierten Daten Kaufentscheidungen trifft. Mit Hilfe einer Künstlichen Intelligenz werden bei diesem Finanzprodukt Zeitungsartikel, Twitter-Posts, Satellitenbilder und sogar die Tonalität von CEO-Aussagen analysiert und anhand dieser Entscheidungen getroffen.
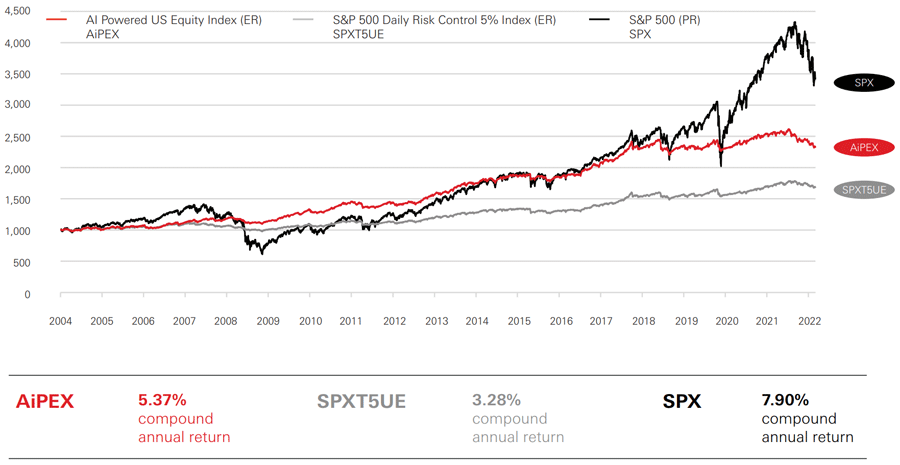
Der auf unstrukturierten Daten basierende KI-Fond AiPEX (rot) der HSBC ist gegenüber anderen Fonds konkurrenzfähig.
Dieses Beispiel zeigt: Die Auswertung unstrukturierter Daten sollte auch durch die Verwendung konventioneller KI-Methoden vorangetrieben werden. In diesem Fall werden zum Beispiel Nachrichtenartikel durch die Verwendung von Natural Language Processing (NLP) ausgewertet und Audioausschnitte von CEO-Aussagen durch intelligente Spracherkennung verarbeitet.
Regulatorik und IT-Infrastruktur sind kritische Fallstricke
Dass jedoch gerade einmal drei Prozent der unstrukturierten Daten in Finanzinstituten verwendet werden, hat insbesondere zwei Gründe. An erster Stelle sind vor allem in Deutschland Geldhäuser durch Datenschutzrichtlinien und andere Regulatorien nicht dazu befugt, jeden Datentyp für die Optimierung der eigenen KI-Modelle zu verwenden. So dürfen beispielsweise Bewegungsprofile oder Audiomitschnitte nur sehr eingeschränkt verarbeitet werden. Welche unstrukturierten Daten Banken mehrwertgenerierend einsetzen können, ist für viele Institute in diesem Kontext nicht klar. Deshalb gilt für Entscheider: Ein regulatorischer Überblick über den eigenen Datenhaushalt ist unverzichtbar, um in der Zukunft gewinnbringende KI-Modelle auf Grundlage diverser Datentypen entwickeln zu können.
Hinzu kommt für viele Geldhäuser eine unzureichende IT-Infrastruktur. Im Gegensatz zu strukturierten Daten, welche auf SQL-Datenbanken gespeichert werden können, müssen unstrukturierte Daten in großen Sammelbecken für unterschiedliche Datentypen gespeichert werden, sogenannten Data Lakes. Der Aufbau einer Speicherstruktur gestaltet sich für viele Banken durch hohe Kosten schwer, denn für unstrukturierte Daten muss unter anderem deutlich mehr Speicherplatz bereitgestellt werden.
Unstrukturierte Daten gehören in jede KI-Strategie
Die Einführung von intelligenten Modellen auf Grundlage von strukturierten Daten beschäftigt Banken weltweit intensiv. Undenkbar für viele Institute, bereits jetzt den Schritt in eine deutlich komplexere Datenwelt zu wagen und die eigenen Künstliche Intelligenzen mit unstrukturierten Daten zu bereichern. Viele Geldhäuser erleben bereits die Modellentwicklung mit konventionellen Künstlichen Intelligenzen als immense Herausforderung.
Trotzdem gilt für Entscheider: Wer zum aktuellen Zeitpunkt keine Kapazitäten für die konkrete Verwendung unstrukturierter Daten hat, muss diese zumindest mittelfristig strategisch berücksichtigen. Beispielsweise durch einen detaillierten Überblick über den internen und externen Datenbestand, und vor allem durch eine auf jegliche Datentypen einstellte Datenstrategie. Denn ohne Vorbereitung auf diesen nächsten Evolutionsschritt der Künstlichen Intelligenz droht vielen Finanzdienstleistern der Verlust der Anschlussfähigkeit in einem zunehmend intelligenten Finanz-Kosmos.



