

Intelligente Modelle haben die Chance, die Finanzbranche zu revolutionieren – von der Betrugserkennung bis hin zu personalisierten Kundenerlebnissen. Der Einsatz von KI-Modellen in der Produktion stellt die Finanzinstitute jedoch vor erhebliche Herausforderungen.

Der Einsatz von Künstlicher Intelligenz in der Produktion stellt Finanzinstitute vor erhebliche Herausforderungen.
Partner des Bank Blogs

Eine initiale Datengrundlage ist geschaffen, das KI-Modell trainiert, validiert – und sogar in die Bestandssysteme integriert. Der Löwenanteil ist also getan, zumindest bis zum nächsten Release des Machine-Learning-Modells.
Weit gefehlt! Denn anders als bei konventionellen Software-Produkten reagieren KI-Modelle direkt auf veränderte Daten, Parameter oder Einsatzgebiete. Um einem Produktionsalptraum vorzubeugen und Aktualität und Korrektheit der eigenen Modelle zu gewährleisten, benötigen Banken einen Machine-Learning-Lifecycle. So können Daten und Modelle vorverarbeitet sowie in Produktion überwacht und dadurch die Qualität des eingesetzten KI-Modells sichergestellt werden.
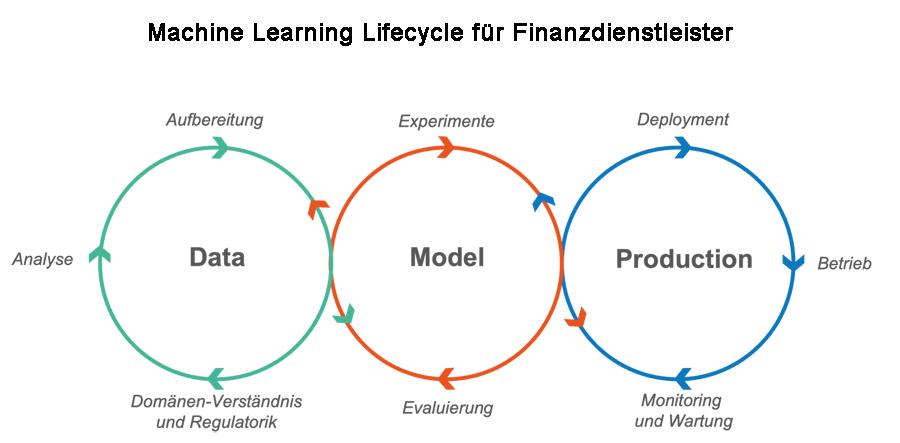
Banken sollten mit Hilfe automatisierter Prozesse für Daten, Modelle und insbesondere produktive Systeme die Qualität ihrer KI-Modelle sicherstellen.
Modelle müssen auf veränderte Gegebenheiten angepasst werden
Die Überwachung von Modellen innerhalb des Bestandssystems ist hinsichtlich der Reduktion von Risiken entscheidend für eine nachhaltige KI-Strategie. Entgegen des verbreiteten Glaubenssatzes „never change a running system“ benötigen Machine-Learning-Modelle regelmäßige Rekalibrierungen, bedingt durch veränderte Umstände in der entsprechenden Domäne. Der Grundsatz hier lautet: „Regularly change a running system“.
Gründe für Anpassungsbedarf bereits entwickelter KI-Modelle sind in der Regel Veränderungen der produktiven Daten, die ab einem gewissen Zeitpunkt von der Trainingsdatenbasis signifikant abweichen. Dadurch sind gegebenenfalls gelernte Muster nicht mehr akkurat oder es sind neue Muster entstanden, welche im Trainingsdatensatz noch nicht existierten. Dies kann beispielsweise für ein Fraud-Detection-System gelten, welches eine neue Betrugsmasche erlernen muss, um verdächtige Zahlungen zu identifizieren.
Ereignisbasierte Warnungen minimieren Modell-Risiken
Im Regelfall werden Modelle in wiederkehrenden Abständen neu kalibriert, sodass stets eine hohe Zuverlässigkeit der generierten Voraussagen sichergestellt ist. Ein solches Vorgehen bildet den Grundstein für aktuelle und zutreffende KI-Modelle, da in festen Zeitabständen Fehler identifiziert und bereinigt werden können.
Je nach Anwendungsfall kann es darüber hinaus notwendig werden, die produktiven Modelle ereignisbasiert zu optimieren. Denn durch Overfitting, also die Anpassung einer Künstlichen Intelligenz an spezifische Inhalte seiner Trainingsdaten, können Modelle auch unerwartet in Produktion fehlerhafte Ergebnisse liefern. Prominente Beispiele hierfür sind ein Twitter-Bot von Microsoft, der nach wenigen Tagen fast ausschließlich rassistische oder antisemitische Tweets absetzte, oder ein Recruiting-Programm von Amazon, das Minderheiten bei der Einstellung diskriminierte. In kritischen Anwendungsfeldern sind Entscheider somit gut beraten, anhand kontinuierlicher Tests in Produktion mit Hilfe von Kennzahlen Abweichungen zur Norm zu identifizieren, um schnell reagieren zu können.
Backup-Modelle auch regulatorisch notwendig
Damit Finanzunternehmen im Ernstfall die betroffene Anwendung nicht gänzlich offline nehmen müssen, sollten sie ältere KI-Modellversionen vorhalten, auf die sie dann zurückgreifen können. Idealerweise wird diese Historisierung bereits während der Modellauswahl durchgeführt, sodass ein breites Spektrum an Trainingsansätzen und Muster-Zusammensetzungen im Modell-Archiv vorhanden ist.
Eine entscheidende Rolle hierbei spielt neben den Backup-Modellen selbst die Dokumentation der Trainingsvoraussetzungen wie der Hyperparameter, der Trainingsumgebung und der verwendeten Datengrundlage. Insbesondere für kritische Use Cases schaffen Banken dadurch die notwendige Grundlage, um der von ihnen geforderten Auskunftspflicht nachzukommen. Durch die Speicherung verwendeter Modelle haben Geldhäuser somit die Möglichkeit, unzutreffende Künstliche Intelligenzen in Echtzeit auszutauschen und gegenüber der Aufsicht oder den eigenen Kunden Auskunft über Einzelentscheidungen zu geben. Ein Beispiel wäre das Kreditrating einzelner Personen.
Automatisierte Datenverarbeitung als Grundstein für zuverlässige Modelle
Der Großteil der notwendigen Vorarbeit zur Inbetriebnahme eines KI-Modells besteht im Verständnis, der Analyse und Aufbereitung der im Finanzinstitut vorhandenen Daten. Am Anfang steht die einmalige manuelle Auswertung des Datenhaushaltes, welche die Daten insbesondere in Kontext zu spezifischem Domänen-Know-how setzt. Ist dies erledigt, gibt es für Manager im Rahmen eines Machine-Learning-Lifecycles zwei Top-Prioritäten: Die Speicherinfrastruktur und die automatische Bereinigung der Daten.
Der schnelle Zugriff auf die gesammelten Daten eines Geldhauses ist ein wichtiger Baustein für jegliche Weiterverarbeitung, also auch für das Modelltraining und somit für produktiv einsetzbare Machine-Learning-Modelle. Durch eine performante IT-Infrastruktur kann so beispielsweise die fristgerechte Rekalibrierung eines Modells sichergestellt werden. Viele Finanzdienstleister setzen zu diesem Zweck sogenannte NoSQL-Datenbanken ein, welche Daten teilweise redundant speichern, dafür aber einen schnellen und unkomplizierten Zugriff sicherstellen.
Aufbauend auf dieser Infrastruktur können zusätzlich Schritte der Datenvorverarbeitung in regelmäßigen Abständen automatisiert durchgeführt werden. Dies gilt insbesondere für statistische Auswertungen der Datenbasis, welche im Trainingsschritt für die Identifizierung von Modell-Features genutzt werden können. Aber auch Anpassungen im Datenbestand sind automatisiert möglich: zum Beispiel die Bereinigung ungültiger Werte, die Normalisierung einzelner Datumsfelder oder die Anreicherung mit externen Informationen.
Automatisierte Machine-Learning-Prozesse sichern Aktualität der produktiven Modelle
Um potenzielle Imageschäden und finanzielle Risiken zu verhindern, sind Banken gut beraten, KI-Modelle im produktiven Betrieb ständig anhand bestimmter Kennzahlen zu überwachen. So können sie bei kritischen Abweichungen schnell eingreifen und die eingesetzten Modelle passgenau rekalibrieren. Durch die Einführung von Modell- und Datenversionierung sowie Machine-Learning-Lifecycle-Methoden können Entscheider somit eine zuverlässige Umgebung für den produktiven Betrieb ihrer KI-Anwendungen sicherstellen, welche entscheidende Zulieferaufgaben automatisiert übernimmt.


