Banken sammeln heute viele Kundendaten. Um diese aber richtig einsetzen zu können, müssen sie zu relevanter Information verknüpft werden. Mit Hilfe dieser Kundeninformationen lassen sich personalisierte Kundenangebote vorschlagen, welche die Kosten pro Kunde senken und Prozesse optimieren können.


Banken verfügen über eine Vielzahl an Kundendaten, die sinnvoll verknüpft zu einer strategischen Informationsbasis und damit zu einem Wettbewerbsvorteil werden.
Partner des Bank Blogs


Ich möchte Ihnen Urs vorstellen. Urs ist Geschäftsleitungsmitglied der Privatbank Zürichsee. Sein Hauptziel ist es, die Anzahl Kunden pro Kundenberater zu erhöhen, um dadurch Kosten zu sparen. Viele Kundenberater verwenden einen großen Teil ihrer Zeit damit herauszufinden, welche Kunden angesprochen werden sollen und welche Themen sie interessieren könnten. Urs‘ neuer bester Freund Patrick, CIO der Privatbank Zürichsee, meint das Problem allein mit Daten lösen zu können.
Banken verfügen über eine Vielzahl von Kundendaten
Patrick erklärt, dass die Bank über Jahre hinweg einen enormen Berg an Daten gesammelt hat. Dieser Berg beinhaltet Transaktionen, Positionsdaten, Steuerdaten, CRM Informationen, eBanking Nutzerdaten, Emails, Telefongespräche und schriftliche Korrespondenz. Einzeln betrachtet sind diese Daten zwar interessant, aber nicht sonderlich wertvoll. Informationen, die eine Komplettbetrachtung des Kunden erlauben, entstehen erst, wenn die Daten verknüpft werden. Mit einem solchen Netzwerk an Informationen lassen sich komplexe Fragen beantworten. Zum Beispiel:
- Wie oft stand der Kunde in Kontakt mit der Bank? Wie hat sich die Aktivität im Verlauf der Zeit geändert? Gibt es mehr oder weniger Kontakt?
- Wie denkt der Kunde über die Bank und wie beeinflusst diese Meinung die Anzahl bzw. das Volumen seiner Transaktionen? Wie viel neues Geld bringt der Kunde – wie viel wird er bringen?
- Besteht die Gefahr, dass der Kunde die Bank verlässt?
Urs freut sich über die gute Nachricht, ist es doch genau das, was er sich schon lange für seine Kundenberater gewünscht hat. Er will also mehr darüber erfahren, wie so etwas umgesetzt werden könnte.
Der Schlüssel liegt in der Verbindung von Daten aus verschiedenen Systeme durch Identitätsmerkmale
In einer perfekten Welt hätte eine Person in allen Systemen die gleiche Identifikationsnummer. Da wir aber nicht in einer perfekten Welt leben, besitzen einige spannende Datenquellen keine eindeutigen Identifikationsmerkmale. Ein Telefonanruf ist beispielsweise nicht eindeutig, da die Nummer von mehreren Kunden verwendet werden könnte. Aus diesem Grund wird ein Merkmal benötigt, um jedes System zu verbinden.
Betrachten wir dieses Problem an einem typischen Bankkunden – sein Name, Hans.

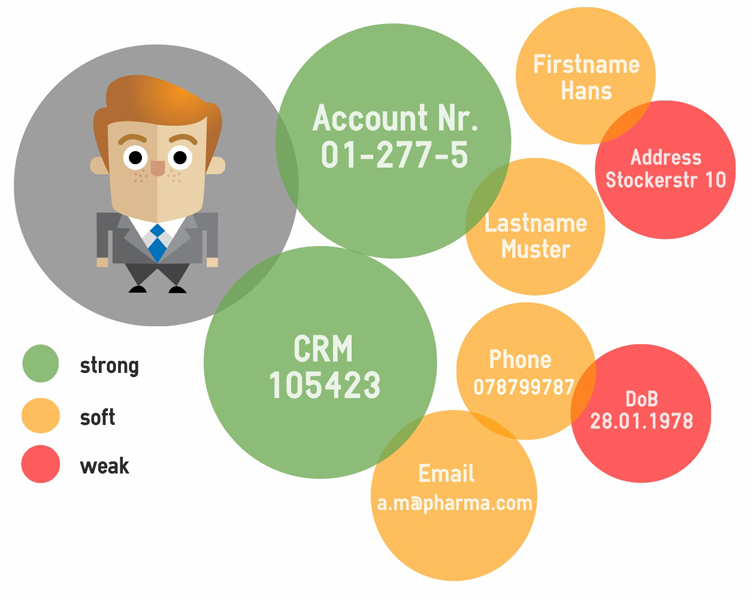
Hans ist ein typischer Bankkunde mit einer Vielzahl von Daten unterschiedlicher Merkmale
Hans besitzt diverse und uns bekannte identifizierende Eigenschaften – Name, Kontonummer, CRM ID oder Geburtsdatum. Einige dieser Eigenschaften sind stärker identifizierend als andere. So ist die Kontonummer eindeutig, das Geburtsdatum alleine aber nicht. In Kombination können schwache Eigenschaften aber trotzdem zu einer nahezu eindeutigen Identifikation führen. Dies nützen wir aus, um Kunden über mehrere Systeme identifizieren zu können.
Wenn wir dieses Prinzip auf eine eintreffende E-Mail anwenden, sieht das folgendermaßen aus: Die untenstehende E-Mail enthält zwei Informationen (Kontonummer, Name), die sich Hans zuordnen lassen – damit stammt diese Mail mit hoher Wahrscheinlichkeit von Hans. Den Prozess des Durchsuchens aller existierender Daten und der Herstellung einer Verbindung zum Kunden nennen wir Crawling.


Vereinfachtes Beispiel für eine E-Mail-Nachricht eines Kunden an seine Bank
Zusätzlich enthält die Mail jedoch noch viele weitere Informationen! Der Absender der Mail ist eine nicht bekannte Adresse, die nun dem Profil von Hans hinzugefügt werden kann. Es könnte sich aber auch um einen Betrugsversuch handeln, in diesem Fall ist es sehr wichtig, die Mail dem Kunden zuzuordnen, damit entsprechende Sicherheitsmaßnahmen ergriffen werden können. Das Erweitern von bekannten Eigenschaften nennt sich Learning. Dieses Learning führt dazu, dass Identitätsdatenbanken digitalisiert aufgebaut werden können.
Beispiel: Hans stöbert seit einiger Zeit auf unserer Webseite. Diese Aktivitäten werden natürlich registriert, können ihm aber nicht zugeordnet werden. Eines Tages entscheidet sich Hans, eine Mail über das Kontaktformular zu senden und mit der Bank in Verbindung zu treten. Ab diesem Moment wird es möglich alle bisherigen und zukünftigen Bewegungen von Hans auf der Webseite eindeutig zuzuordnen. Wieso? Jede Bewegung enthält eine eindeutige Nummer, die auch in der Anfrage über das Kontaktformular enthalten ist.
Hört sich sehr teuer und schwierig an?
Urs gefällt zwar was er hört, fragt sich aber, was so eine Lösung kosten soll. Patrick, der CIO, erklärt er habe bereits ein bestehendes Proof of Concept. Das PoC basiert auf dem ti&m analytics Framework. Um zu evaluieren was möglich ist, besuchen Patrick und Urs ti&m im Rahmen eines Lab-Visits – für weitere Inspiration und Brainstorming wie eine Umsetzung ablaufen könnte.
Risiken des Datenmanagements für Banken?
Weitere wichtige Abklärungen stehen an: Risiken. Firmen im Allgemeinen und Banken im Speziellen müssen Reputationsrisiken sowie rechtliche und Compliance-Aspekte immer im Blick haben. Datenschutzgesetze erlauben es, interne Daten zur Klassifizierung und zum Profiling zu verwenden. Im Gegenzug hat der Kunde das Recht zu erfahren, welche Daten von ihm gespeichert sind, wie sie verwendet werden und diese gegebenenfalls löschen zu lassen. Das Bankgeheimnis verbietet die Verbindung zwischen Kunde und Bank gegenüber Dritten offen zu legen. Da die Informationen aber ausschließlich intern verwendet werden, wird nicht dagegen verstoßen.
Dem Kunden proaktiv und transparent aufzuzeigen, welche Informationen über ihn gespeichert und verwendet werden, kann zu einem Reputationsgewinn führen. Der Kunde fühlt sich ernstgenommen und hat die Kontrolle über seine Daten. Personalisierte Preise werden allerdings noch nicht akzeptiert. Daher muss die Verwendung von Informationen gegen außen sehr vorsichtig passieren. Ein weiteres Risiko besteht, wenn sämtliche Kundeninformationen an einem Ort archiviert werden. Dieses kann aber minimiert werden, wenn Informationen anonymisiert und erhöhte technische als auch organisatorische Sicherheitsmaßnahmen ergriffen werden.
Schlussfolgerung
Urs ist überzeugt! Ein solches System wird ihm eine 360° Sicht auf seine Kunden ermöglichen. Sein Ziel die Kosten pro Kunden zu senken ist erreicht. Zusätzlich erlaubt es ihm die Qualität des Kundenservices zu optimieren und durch Cross- und Up-Sales mit personalisiertem Offering auch den Umsatz zu steigern. Und das sind nur einige der vielen Möglichkeiten. Mit Hilfe von Big Data Technologien können spannende neue Business Modelle erschlossen und Kosten weiter gesenkt werden.
Für mehr Informationen begrüßen wir Sie gern zu einem Lab-Visit bei ti&m.

Partner des Bank Blog – ti&m
Mehr über das Partnerkonzept des Bank Blogs erfahren Sie hier.